

学会反想的国产大模子,真变强了?
真的能够像东谈主类一样进行逻辑推理的大模子,距离咱们还有多远?
跟着OpenAI推出更侧重推理身手的 o1大模子,推理大模子正成为行业新的竞争标的。本周一,月之暗面推出的Kimi探索版,成为国产推理大模子的最新代表。
让大模子学会推理的决窍是什么?各家厂商皆提到了一个要津词——反想。通过将复杂问题一步步拆分,何况对每一步的输出收尾进行反想教育,是镌汰大模子幻觉的有用蹊径。而这样的想路,看上去与东谈主类的逻辑推理确乎有一定相似性。
不外经过实测,咱们发现现存大模子的逻辑推理身手仍然难以让东谈主快意,这背后可能仍然绕不开大模子底层道理的摒弃。
但道理的是,为了提高推理身手,国产大模子在使用器用的路上越走越远,反而可能是当下最现实的大模子落地蹊径之一。
推理大模子,真的会作念题吗?
上周五,月之暗面晓示推出Kimi探索版,并于本周一肃肃上线。
据官方先容,Kimi探索版具备AI自主搜索身手,可以模拟东谈主类的推遐想考经由,多级解析复杂问题,实践深度搜索,并即时反想矫正收尾,提供更全面和准确的谜底,匡助你更高效地完身分析调研等复杂任务。
那么实测来看,Kimi探索版实力究竟如何?
谈到推理身手,东谈主们时时伊始猜想的是数学。好多测评皆使用高级数学题目去测试大模子的推理身手,何况时时能够取得可以的成果。
不外从实用层面来看,大部分用户的需求并不是求解高数,而是贬责日常生涯中的应用题。
是以,咱们蓄意让Kimi替最近上市的新车乐谈L60算笔账。
蔚来换电体系下独到的BaaS电板租借决策,让不少耗尽者在绸缪用车本钱的时刻也感到头疼,乐谈L60发布会后,到底如何买更合算引起了网友强烈商议,不少网友甚而搬出了专科的司帐常识。
咱们问Kimi的问题是这样的:分析乐谈L60车辆采用BaaS决策下的每年用车本钱,BaaS决策和电板买断决策哪个更合算。
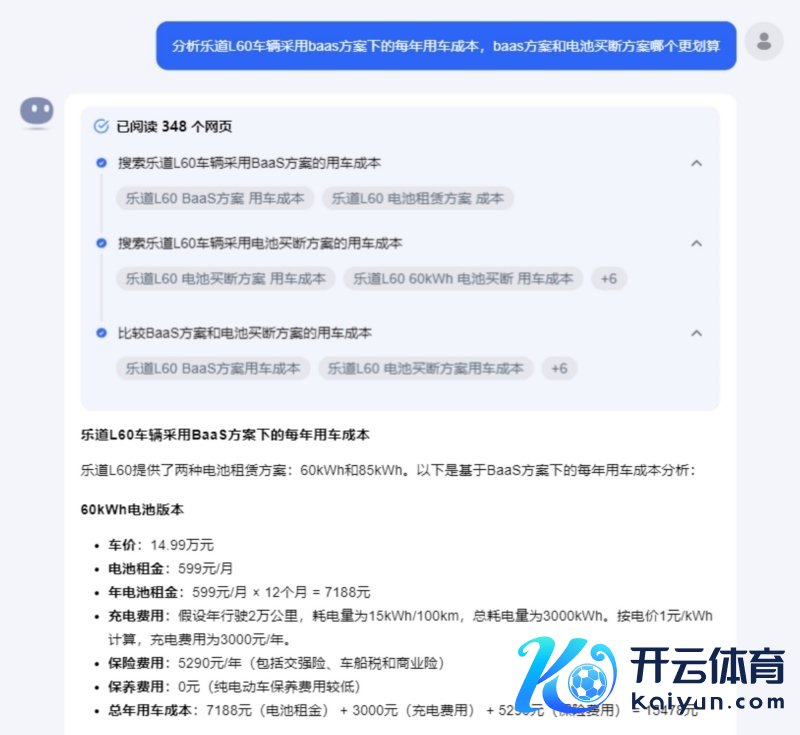
可以看到,Kimi正确贯穿了BaaS的含义,天然莫得刚毅到乐谈是换电而不是充电,不外按充电本钱算也莫得太大收支,所有这个词逻辑基本是澄莹的。
问题在于,天然一运转提到了购车价钱,但是在总用车本钱的绸缪上,Kimi却并莫得加上购车本钱的折旧,没达到咱们想要的成果。
于是,咱们条目Kimi把折旧本钱讨论进去,收尾是这样的:
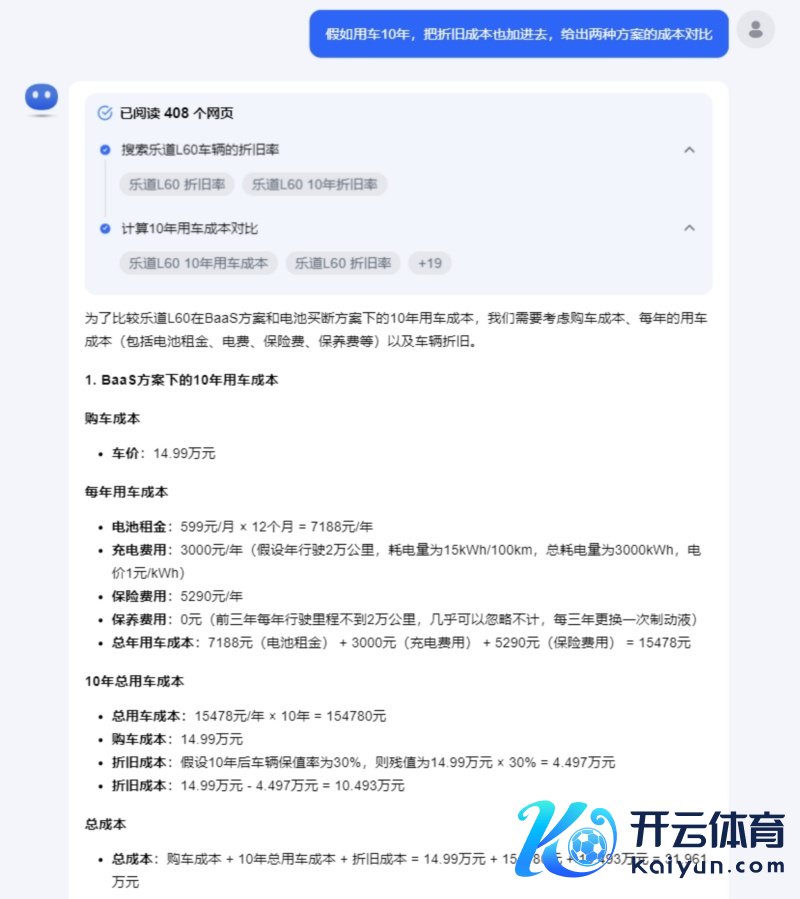
在临了的论断里,Kimi对购车价钱和折旧本钱进行了相通绸缪,明显是乌有的。而这个乌有,刚巧阐发Kimi关于本钱和折旧的逻辑贯穿还存在不及。
当作对比,咱们用ChatGPT-4o mini测试了疏导的问题,发现4o mini可以正确贯穿包括折旧、BaaS在内的各项本钱的逻辑,关联词却莫得正确得回车辆的价钱。

也即是说,Kimi并莫得弘扬出比GPT-4更好的逻辑身手,但是在中语信息检索身手上却愈加优秀。事实上,后者亦然Kimi真的的刚毅所在,后头咱们会再次商议这少量。
不外在此之前,咱们还发现了一个相对小众的选手——学而想九章大模子,也相等值得热心。
提到学而想,巨匠皆知谈它是以教培起家,尤其擅长数学教学。而九章大模子也接纳了学而想的特长,专攻阐发领域,何况声称有更好的数学身手。
当咱们以上述问题测试九章大模子时,它的弘扬终点出色——不仅能正确贯穿车辆残值、本钱均派等逻辑宗旨,还具体得回了乐谈BaaS“满四减一”优惠、执行电耗水对等信息,因此给出的谜底更能贬臆造题。

但好意思中不及的是,它并莫得给出车辆折旧的具体数字,导致最终莫得输出一个明确的谜底。
这究竟是一个裂缝,如故优点?其实从逻辑来看,九章这样作念的原因,应该是通常出于“具体问题具体分析”的理念,由于我方没方针详情干系车辆的具体折旧率,因此就径直阐发我方的省略情,充分保证了谜底的严谨性。
看上去,九章的确更像是一个严谨、可靠的数学模子。
AI可能还莫得学会推理
强化大谈话模子的推理身手,在时间上是如何达成的?巨匠皆提到了一个要津词——反想。
月之暗面方面指出:就像东谈主一样,Kimi探索版可以借助反想身手,来普及和矫正答复的质料。靠近绽开探索型问题,Kimi探索版发现第一次答复的信息存在缺失,会主动补充答复更多。靠近数字干系的搜索问题,Kimi了解更多信息后若是发现了数据冲突,则会实时补充提供多方视角的信息供参考决策。

从上头的演示中可以看到,Kimi会把我方的想考经由展示出来,让用户明确看到我方进行了一次补充检索。
九章大模子负责东谈主白锦峰进一步解释说,同大模子肖似,东谈主类在少小时间通常衰退逻辑身手,会产生幻觉。但跟着东谈主类的成长,会逐渐学会逻辑推理,让我方的不雅点在逻辑上自洽,并拿不雅点去跟照旧存在的事实进行校验,从而摈弃幻觉。
白锦峰默示,现在大谈话模子的第一性道理是Next Token Prediction,也即是通过展望下一个字符的格式给出谜底,而这种展望是基于概率的,这决定了大模子一定会有出错的概率。
为了普及准确率,现在的推理大模子普遍应用了CoT(想维链)和Votingamp;Verifier两种算法,前者将复杂问题拆分为多个风物,后者则关于每一步的收尾进行反想,多作念几次教育来找到一致性最高的谜底。
这两种算法师法了东谈主类想维格式中的校验经由,但其实仍然是基于概率,而不是逻辑推理。白锦峰指出,为了真的保证收尾的正确性,大模子还需要应用定律的时间,例如学会使用数学定律来贬臆造题。
但是在应用定律方面,大模子仍然存在根人道的难点。白锦峰例如说,像加法交换律(a+b=b+a)这样通俗的定律,东谈主类可以径直贯穿公式,但是大模子只可通过穷举大批的案例(1+2=2+1等)来悟到这个法则。
因此,关于面前的大模子时间能否真的达成推理身手,好多东谈主并不乐不雅。好意思国著名AI科学家Yann LeCun近日就厉害地默示,当下的模子“似乎在进行推理,但执行上它们仅仅在相通照旧教育过的信息”,按照现存教育格式,不管几许GPU皆不会让咱们达成AGI。
苹果AI团队的最新臆度也以为:大谈话模子在疏导问题的不同版块上弘扬出高性能互异、难度稍微加多时性能大幅下跌以及对无关信息的敏锐性,标明其推理身手很脆弱。它可能更像是复杂的模式匹配,而不是真的的逻辑推理。
从大模子到Agent
尽管以AGI的步调来量度,现在的推理大模子还远远不够完善,但是从实用层面,国产大模子正在这轮推理竞赛展现出了一个迫切进化——调用器用。
例如,九章大模子在贬责数学问题的时刻,采用了一个看似原始却终点实用的方针——径直调用绸缪器。就像东谈主类一样,学会使用器用,亦然AI应当具备的身手。
Kimi调用的器用则是搜索引擎。Kimi探索版在答复问题时,最高能够搜索并精读500个网页,相较于此前版块普及了10倍。
而且咱们在实测中发现,Kimi列出的参考页面普遍皆来自较为泰斗的站点,内容质料也相对较高。在绽开性的问题中,Kimi能够充分保证输出的客不雅和准确性,这才是探索版给咱们印象最长远的场地。
Kimi 探索版居品负责东谈主默示,“若是 Kimi 搜不到的信息,那简略率用户也很难我方通过传统搜索引擎找到。未来搜索引擎会成为AI更擅长调用的器用,东谈主只需要专注于建议好的问题,AI就可以纠合模子自身的身手在庞大的互联网中自主海量搜索,不断反想迭代,更精确地找到所需谜底。”
关于大部分闲居用户来说,这话并不夸张。
从实质上讲,调用器用使得这些模子更接近于AI Agent的宗旨。尤其是关于Kimi探索版,相等于替用户完成了网页检索的任务,何况能够匡助用户去除搜索引擎中大批的低质料和营销内容,实用性极强。
若是说,面前的AI表面自身就摒弃了大模子难以达成真的的逻辑身手,那么在表面冲破之前,如何最大化模子的实用性,让AI从Copilot向Agent尽可能地迈进,即是当下最迫切的命题。
此外,从Kimi、九章的弘扬来看,国产大模子如今不绝普及实用性的格式,并不一定是加多领域,或者建议什么独到的算法,而是通过专注于我方最擅长的垂直领域来普及准确率,并酿成独到护城河。
白锦峰例如说,关于阐发大模子来说,能答对问题和能教勤学生之间,仍然存在分离。例如通常是除法,用除号如故用分号来默示,在教学中即是不一样的。关于小学生来说,因为还莫得学过分数,是以用分号即是乌有的答复。因此,学而想期骗我方恒久累积的讲义和教师资源,能够作念出更好的阐发大模子。
专注垂直,也能够让本钱愈加可控。学而想方面东谈主士向不雅察者网直言,大模子初期过问是不能幸免的,现在也看不到径直的请教,但过问又是必须要作念的,不然比实时间闇练再发力,早就失去了上牌桌的契机。
但是学而想并莫得聘用去我方研发基座大模子,而是基于开源大模子的基础,在百度云上进行千卡领域的教育,以可控的本钱达成了可以的性能。
因此,国产推理大模子当下给咱们的最大启示,未必仍然是实用为王。